Guide to Extracting Data from Unstructured Documents
Published on: Aug 13, 2024

Written by: Admin
Extracting Data from Unstructured Documents: An Educational Guide
Learn to extract valuable data from unstructured documents like PDFs and scanned images. Explore techniques and tools to transform raw data into actionable insights.
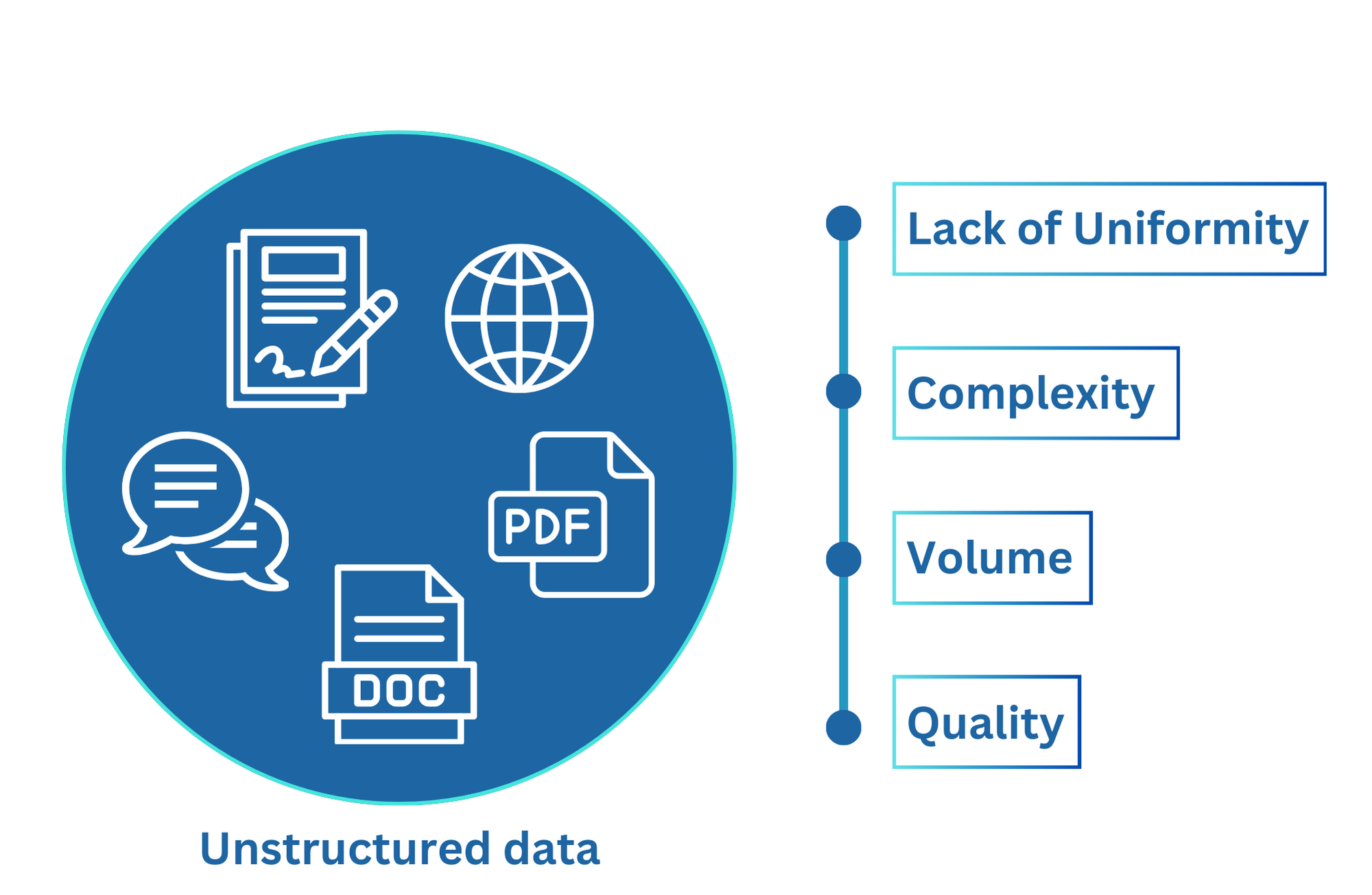
Understanding Unstructured Data
Unstructured data refers to information that does not have a pre-defined data model or is not organized in a systematic manner. Examples include:
- Text documents (e.g., PDFs, Word files)
- Emails and chat logs
- Social media posts
- Images and scanned documents
Challenges of Unstructured Data Extraction
- Lack of Uniformity: Unstructured documents vary widely in format and content.
- Complexity: Extracting meaningful information often requires understanding the context.
- Volume: Handling large volumes of unstructured data can be resource-intensive.
- Quality: Unstructured data may contain errors, inconsistencies, or irrelevant information.
Techniques for Data Extraction
- Optical Character Recognition (OCR)
- Description: OCR converts different types of documents, such as scanned paper documents, PDFs, or images captured by a digital camera, into editable and searchable data.
- Tools: Tesseract, ABBYY FineReader
- Example: Extracting text from a scanned invoice to digitize financial records.
- Natural Language Processing (NLP)
- Description: NLP techniques are used to process and analyze large amounts of natural language data.
- Tools: SpaCy, NLTK, GPT-4
- Example: Extracting key information such as dates, names, and locations from legal documents.
- Regular Expressions (Regex)
- Description: Regex is a sequence of characters that defines a search pattern, often used for string matching within texts.
- Tools: Built-in libraries in programming languages like Python, JavaScript
- Example: Extracting phone numbers or email addresses from a text file.
- Machine Learning (ML) Models
- Description: ML models can be trained to recognize patterns and extract specific information from unstructured data.
- Tools: Scikit-learn, TensorFlow, PyTorch
- Example: Classifying and extracting different types of information from medical records.
- Document Parsing Libraries
- Description: Libraries designed to parse and extract data from specific document formats.
- Tools: PDFMiner, Apache Tika, BeautifulSoup
- Example: Extracting metadata and text from PDF documents.
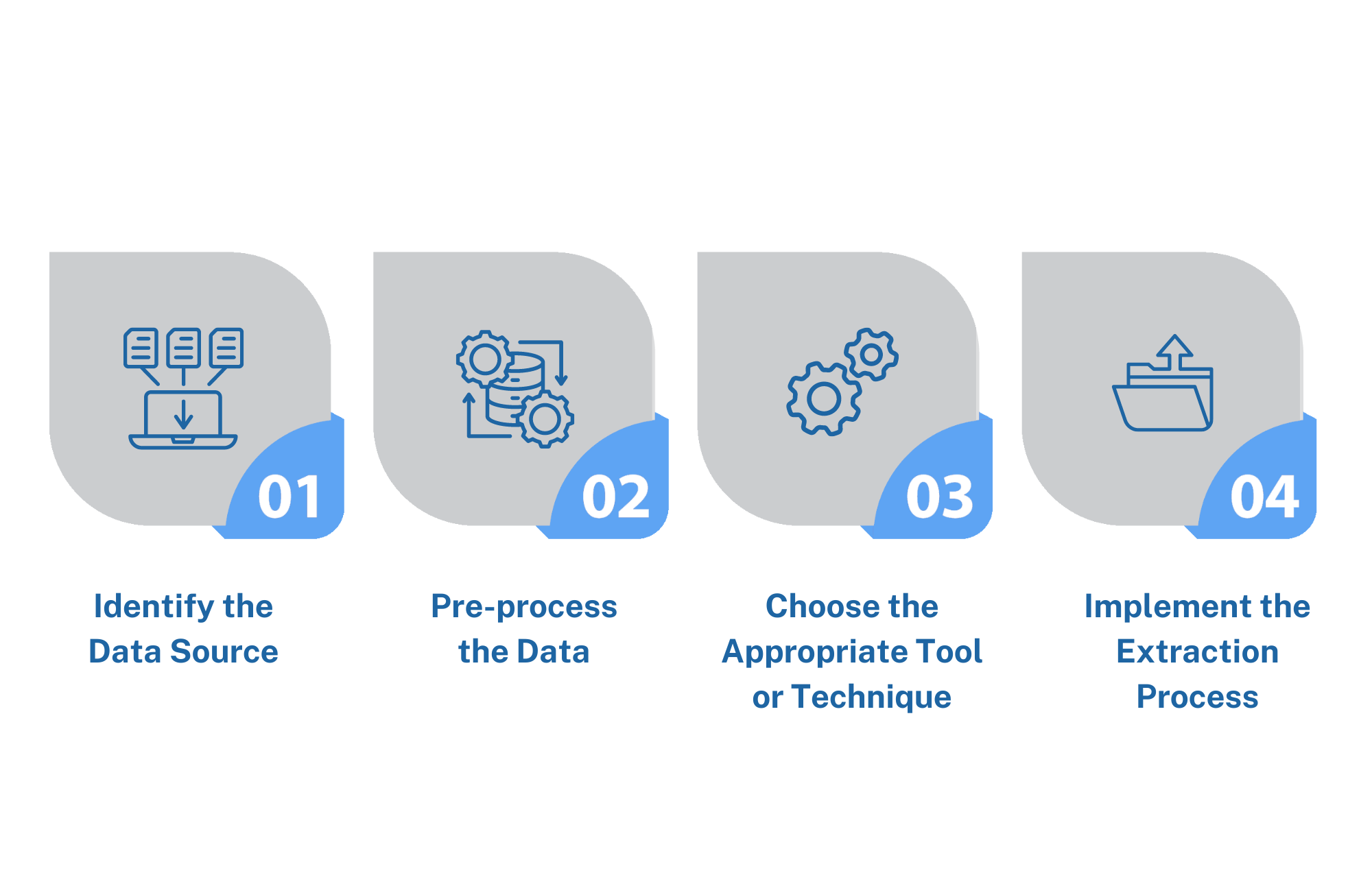
Practical Steps for Extracting Data
- Identify the Data Source
- Determine the type of unstructured document you are working with (e.g., PDF, image, text file).
- Pre-process the Data
- Clean the data by removing noise, correcting errors, and standardizing formats.
- Example: Converting all text to lowercase, removing special characters.
- Choose the Appropriate Tool or Technique
- Select a tool or technique based on the nature of the data and the information you need to extract.
- Example: Use OCR for scanned images, NLP for text-heavy documents.
- Implement the Extraction Process
- Write and execute the code or use software tools to extract the desired information.
Example (Python code using Tesseract OCR):
from PIL import Image
import pytesseract
# Load an image from file
image = Image.open('document.jpg')
# Perform OCR on the image
text = pytesseract.image_to_string(image)
print(text)
5. Post-process the Extracted Data
- Clean and structure the extracted data for further analysis or storage.
- Example: Parsing extracted text to identify and organize key information into a structured format (e.g., JSON, CSV).
Advanced Techniques
- Named Entity Recognition (NER)
- Identify and classify entities (e.g., names, dates, locations) within text.
Example (using SpaCy):
import spacy
# Load the SpaCy model
nlp = spacy.load('en_core_web_sm')
# Process the text
doc = nlp("John Doe visited New York on 10th January 2020.")
# Extract entities
for entity in doc.ents:
print(entity.text, entity.label_)
2. Language Models
- Use advanced language models like GPT-4 for context-aware data extraction.
- Example: Summarizing a long document or extracting answers to specific questions.
Extracting data from unstructured documents is a critical skill in today's data-driven world. By leveraging various tools and techniques such as OCR, NLP, regex, and machine learning models, one can transform unstructured data into valuable insights. The choice of method depends on the specific requirements and nature of the documents being processed. With the right approach, the vast amounts of unstructured data can be effectively harnessed to drive decision-making and innovation.
References
- Tesseract OCR: GitHub Repository
- SpaCy: Official Website
- NLTK: Official Website
- PDFMiner: PDFMiner Documentation
- Apache Tika: Apache Tika
- TensorFlow: TensorFlow
By understanding and applying these techniques, you can unlock the hidden potential of unstructured data and gain a competitive edge in your field.

